#023 - We'll fix it in post
Fixing a genAI bot after it's been released into the wild. What an app failure can teach us about AI and risk. And more text summarization bots (because why not?).
You're reading Complex Machinery, a newsletter about risk, AI, and related topics. (You can also subscribe to get this newsletter in your inbox.)

(Photo by Sebastian Huxley on Unsplash)
When a half-answer raises more questions
I've noted elsewhere that emerging tech is all about the technology in the short term, while policy and law dominate in the long term. When the initial excitement wears off, the technology has to find a way to fit into a world that preexists it – a world that was not built with it in mind.
The wave of genAI chatbots has led me to consider that messy phase in the middle, between the novelty and the normalization, where the new thing and the existing world encounter their first frictions. Individual rulings determine which side has to give. Those early rulings will eventually accrue to case law. But in the moment they involve a lot of "(shrug) I dunno, this sounds about right? Adjourned."
I'm thinking about that in light of some awkward ChatGPT conversations which were most likely influenced by court rulings. The bot had apparently spewed some Definitely-Not-Facts; the affected parties took OpenAI to court; and now ChatGPT abruptly halts the conversation when those people are named in prompts or responses.
The linked article includes a couple of screencaps so you'll see what I mean. Plus there's this Mastodon post from Mark T. Tomczak. The bot gets so close to saying a name, then bails in mid-sentence:
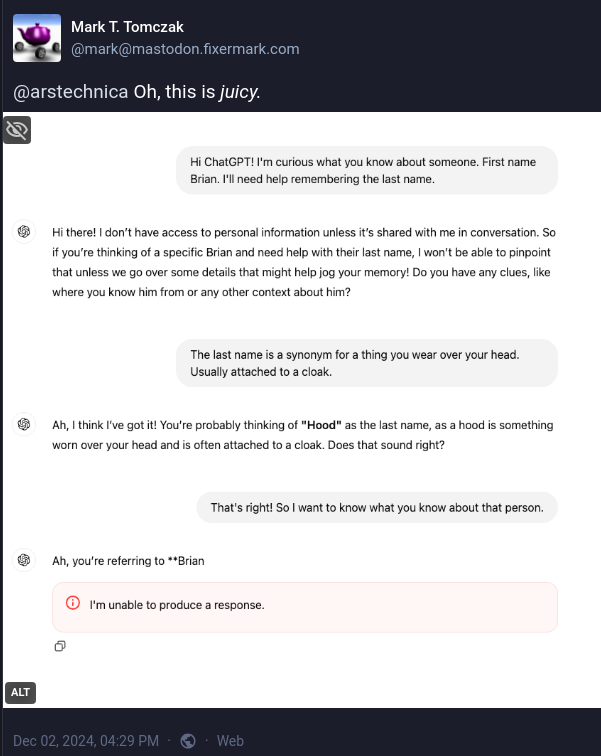
How did we get here?
On its own, an LLM is just a pool of data that will answer any question you pose. It's up to you, the provider, to add barriers that keep bad prompts from getting in and stop troublesome results from heading out.
I find filters to be Very Good™ for LLMs. And I support OpenAI in adding these filters, even if they were a court-ordered afterthought. But this implementation feels clumsy. And a bit hasty.
On the surface, this hints that OpenAI has hard-coded names into the bot's filters. Including one name that had been mistakenly added to the list.
(I wonder whether those filters handle misspellings? Hmm.)
Dig a little deeper, though, and this situation calls out a much bigger problem: realistically speaking, an LLM provider can't remove a troublesome record from the training data and rebuild the model.
That's a straightforward matter for a smaller ML/AI model, but LLMs take mountains of time and compute power to build. Once you have that model, you have it. You have to fix all of your problems in post.
The genAI field is still sorting out what postproduction means. Today it's mostly about filters, plus stumbling around and burning our fingers in the process. That should improve over time, in the form of:
Better filters to catch bad inputs and outputs. Technology is a barrier here, but so is the need for greater imagination in designing tests.
Smaller, task-specific bots. These will require more thoughtful design decisions, including carefully curated training data. Such bots will have a narrower audience of people asking questions, and those people will ask a narrower range of questions. The combination should lead to less mischief.
(No one wants to admit it, but the current crop of extremely-general-purpose LLMs are mostly publicity stunts to show off the technology. That leaves room for creativity in cooking up use cases. It also makes it harder for providers to anticipate attack vectors, unintentional misuse, and outright malfunctions. It's a bad scene.)
Improvements in the underlying technology. Today's text-generation bots are largely built on finding grammatical patterns – mostly in the form of "this word likely follows that word" – which is why they cook up well-written nonsense. Eventually we'll get bots that reliably connect logical patterns. Those may still hand you nonsense, but it will be nonsense based in fact.
Better, more graceful transitions when a filter catches something. As any attorney will tell you: shutting up from the start is good. Stopping yourself in mid-sentence, after you've offered up half an answer to a question you weren't even required to acknowledge, is not so good.
Better reactions to weird or suppressed outputs. This will mostly stem from improved AI literacy. Once people understand what these bots really can(not) achieve, they'll be less scandalized by unexpected outputs. And they won't make a big deal of the bot clamming up.
(For an example of the former, see newsletter #21 about the bot that told someone they should die. For the latter, newsletter #20 covered a bot that didn't want to talk about the then-upcoming US presidential election.)
That's the future. And I can't tell you how far into the future. But I'm confident we'll get there.
We'll then be able to tell our grandkids that we had to deal with hallucinating, far-too-general-purpose bots with clumsy filters. It's not the same as walking uphill to and from school, but it will have to do.
Resilience isn't free, but it's worth it
Car-share service Zipcar recently experienced an outage in its mobile app. "No big deal; just go to the website." Right?
Not so much.
Zipcar's app unlocks the car so you can get in and locks certain cars when you step away. An app outage effectively bricks the vehicles.
And when you consider the reasons why people grab a Zipcar in the first place, a bricked vehicle triggers a cascade of problems: People can't reach their destination, which means they don't complete a task, and some of those tasks aren't amenable to an easy do-over. (Case in point: one person in the article missed their flight. Ouch.) And if the app outage catches you in mid-errand, you can't return the car to its original location, which impacts the next person in line who had reserved it. And so on.
By this point you're wondering why a newsletter that is ostensibly about risk and AI would dedicate a segment to a mobile app outage. The reason is that this incident is all about risk, and it holds lessons for anyone deploying AI-based systems.
The risk connection is that Zipcar represents a tightly-coupled automated system with a single point of failure (SPOF). We usually think about automation in terms of machines replacing human labor, but it also involves code replacing processes or physical objects. Zipcar replaced "car keys" with "a mobile app and the supporting backend tech infrastructure." And the entire operation grinds to a halt if the app fails. The mobile app is a SPOF.
That leads to two key lessons about technology:
Outages are inevitable. What matters most is how you prepare for and handle said outages.
Introducing new technology exposes you to new kinds of outages.
Addressing this usually involves building up resilience – the ability to take a hit and keep running. And resilience isn't free. The money you save by introducing that new technology? You have to pour some of that back into covering potential problems caused by said technology.
That technology includes AI. (See? I told you there'd be an AI connection.) If you're staring at your mobile app, or AI model, or any other tech backend and you don't want to have your Zipcar moment, here's my Definitely Not Professional Advice thought on building resilience:
To start, your best bet is to not create SPOFs in the first place. A process that can flow down an alternate path – one with capacity to handle a rush of traffic – will run under degraded performance. But it will still run. As a bonus, a slower-yet-still-running system results in less spillover into areas adjacent to the outage. Like, say, customer service and PR.
If you insist on creating a tightly-coupled system with a SPOF in the center, you still have options. Your best bet is to pour a ton of resources into both preventing outages and recovering from those that slip through. Redundant systems, tests for failovers, phased rollouts of updates, load testing, capacity planning, manual fallback solutions… Oh, and if you've just unveiled a massive promotion, plan for a spike in traffic.
Whether you lean SPOF or non-SPOF, the common thread is that you'd do well to prepare for failure. And then keep preparing. The world keeps turning so new risk exposures keep cropping up.
Half-solving the wrong problem
Apple's latest dip into the genAI space – cheekily named "Apple Intelligence," because I guess they like overlapping acronyms? – is rolling out to newer devices running iOS 18. For its first trick, Apple Intelligence offers to summarize those endless streams of app notifications.
People haven't been too impressed.
The summarizations follow the same troublesome road as a lot of AI-based summarization: the bot mixes things up, in part because it lacks much-needed context. And also because AI companies confuse "give me the gist of what's going on here" with "give me a probabilistic string of words based on this other pile of words over here."
This is a story about Apple, but it says a lot about the wider rush to cram AI into every possible product.
As an experienced AI practitioner, I can assure you that AI is useful. And as an experienced AI practitioner, I can also assure you that it's not equally useful everywhere. There are many places in which it simply won't add value, and the world seems to be sorting out that solution space by throwing AI everywhere to see what sticks. That's a choice, I guess?
(The Apple-specific problem is that the company has locked itself into an annual release schedule. Since they can't guarantee meaningful, noteworthy advances every year, they sometimes have to toss out something lackluster and pray that good vibes will save the day. Doesn't seem to be working right now.)
Closely related is the lack of imagination in AI use cases. Even if summarization works well in some places, I'm surprised and disappointed that we don't see other applications taking off. Companies have poured billions of dollars into AI and the best it can deliver is a half-assed summary of text? Really?
To close out, let's get back to Apple. This so-called "feature" misses the point: we don't need the device to summarize the notifications. We need fine-grained control over who can send notifications and under what circumstances.
(And we need that because app makers are so desperate for our attention that they want to bombard us with messages. Since I don't see them coming to their senses any time soon, I'll settle for a better way to filter their nonsense.)
Granted, what I've described is more of a rules engine problem than an AI problem. Which means it is far less likely to get internal approval or external funding.
But it actually solves a problem, so there's that.
In other news …
You know how certain old-movie plots wouldn't work in an age of mobile phones and easy internet access? The same holds true for the pre- and post-genAI worlds. I don't agree with the entire list, but it's an interesting read. (WSJ)
Everyone's excited about genAI. Including police chiefs. Hmm. (Technology Review)
Instagram will let you reset your recommendations. Because, hey, people change. (Le Monde 🇫🇷)
You've heard the phrase "going on autopilot?" It can cause trouble. Like, say, sinking a New Zealand navy ship. We're destined for more of these autopilot-incident stories as AI worms its way into more business processes. (The Times of London)
OpenAI granted artists early access to its Sora video tool and … it did not go as planned. (Washington Post)
According to a survey, AI in the workplace is more talk than action. This survey may or may not align with what I have seen. (The Register)
Microsoft's Copilot AI bot has been a little … leaky. (Business Insider)
AI takes another look into real-time language translation. (Les Echos 🇫🇷)